
15. marca na kampusie Google, w Warszawie odbyło się Machine Learning Sumit CEE. Deva miała okazje uczestniczyć w tym wydarzeniu. Uczestnicy wysłuchali 8 prelekcji podzielonych na 2 bloki – wstęp teoretyczny i case studies z przykładami praktycznego zastosowanie machine learning (ML).
Wystąpienie Marcina Malinowskiego miało na celu przybliżenie samej koncepcji ML i jej znaczenia obecnie i w nadchodzącym czasie. Zwrócił uwagę na niejasności, jakimi owiane jest ML, chociażby, że niektórzy nie rozumieją różnicy miedzy programowaniem, a właśnie machine learning. Podkreślał, że to nie jest narzędzie zarezerwowane wyłącznie dla wielkich korporacji, niedostępne dla mniejszych podmiotów. Obecnie, machine learning może pomóc Ci zdobyć przewagę w Twojej branży albo chociaż ułatwić niektóre procesy, a w przyszłości będzie, tak jak wiele innych innowacji kiedyś, obowiązkowym punktem Twoich działań. Jego brak będzie stanowił krok w tył w stosunku reszty świata.
Jak wspomniał Antonio Gulli, jednym z celów Google jest skatalogowanie wszystkich dostępnych informacji na świecie i uczynienie ich łatwo osiągalnymi dla każdego z nas.
Żeby to osiągnąć Google posiada i wciąż buduje nowe centra danych. Poza przechowywaniem danych potrzebne są też wielkie zasoby obliczeniowe, które pozwolą na bieżącą obsługę wszystkich usług, jakie oferuję Google, czyli wyszukiwarki, youtube, gmaila, obsługę całego ekosystemu reklamowego i naszego AdWords, usług związanych z machine learning oraz całej listy innych narzędzi. Wyzwaniem jest takie rozdzielanie tych zasobów obliczeniowych, żeby zapewnić użytkownikom płynne i niczym nie zakłócone doświadczenia. Antonio zwrócił uwagę na kilka problemów związanych z tą bieżącą obsługą – ciągła ewolucja całej infrastruktury – bez przerwy podłączane są kolejne maszyn, część z obecnie eksploatowanych psuje się lub jest czasowo niedostępna, wszelkie proces, które wykorzystują moc obliczeniową mają swoje priorytety – wyniki wyszukiwania muszą pojawić się natychmiast, z kolei wideo na YouTube może się załadować z lekkim opóźnieniem. To ogromne wyzwanie logistyczne już dawno zmusiło Google do korzystania z deep learning (kolejny krok w stosunku do ML). Czyli Google poza dostarczaniem nam narzędzi i usług związanych z ML (o czym dalej), samo na bardzo szeroką skalę je wykorzystuje.
Podstawy i krótką historię ML przybliżył nam Akbur Ghafoor w swoim energetycznym wystąpieniu. Koncepcja sztucznej inteligencji pierwszy raz pojawiła się w roku 1955 na jednej z konferencji naukowych. Od tamtej pory minęło ponad 6 dekad, a my w końcu pokonujemy ograniczenia, które do tej pory blokowały jej rozwój. Mamy co raz mocniejsze komputery z niewyobrażalną (na tamte czasy) mocą obliczeniową, możemy się pochwalić wielkimi zasobami danych (kluczowy składnik w przypadku ML), do których można uzyskać dostęp w łatwy i szybki sposób. To wszystko dało początek samouczącym się regułom i machine learning, jakie znamy dziś.

Prosty przykład pozwolił pokazać, jak niewinne pytanie uruchamia całą „machinę” neuronów w naszych mózgach. Odpowiadamy automatycznie – na zdjęciu widać psa, jednak „w tle” zachodzą skomplikowane procesy.
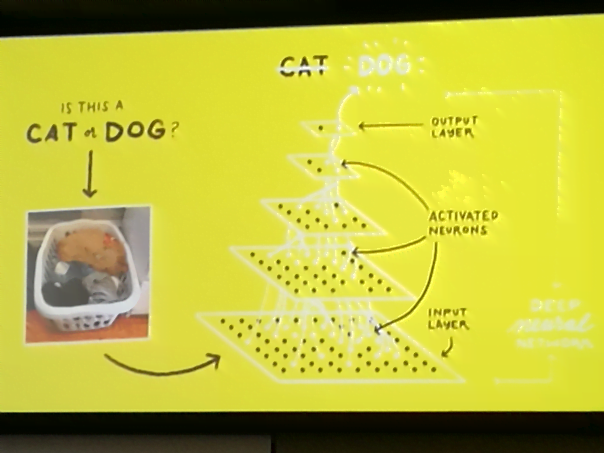

Przyjmujemy informację, jaką jest obraz, dokonujemy jego analiza biorąc pod uwagę takie elementy, jak kolor, kształt, wielkość, faktura itp., następnie na podstawie wcześniejszych doświadczeń, wspomnień, zakodowanych symboli itp., identyfikujemy obiekt na obrazku, jako psa. W przypadku machine learning mamy do czynienia z podobnym procesem – model podejmuje decyzję (w tym wypadku, jakie zwierzę widać na obrazku) na podstawie posiadanych danych. Różnica polega na tym, że nie zbiera swoich „doświadczeń” samodzielnie, a z naszą pomocą – musimy dostarczyć odpowiednich danych, które zostały już przez nas prawidłowo skategoryzowane jako pies lub kot. Na tym etapie model wciąż jest niedoskonały – potrzebuje kolejnych danych, które pozwolą na ocenę czy działa prawidłowo i na ewentualną korektę.
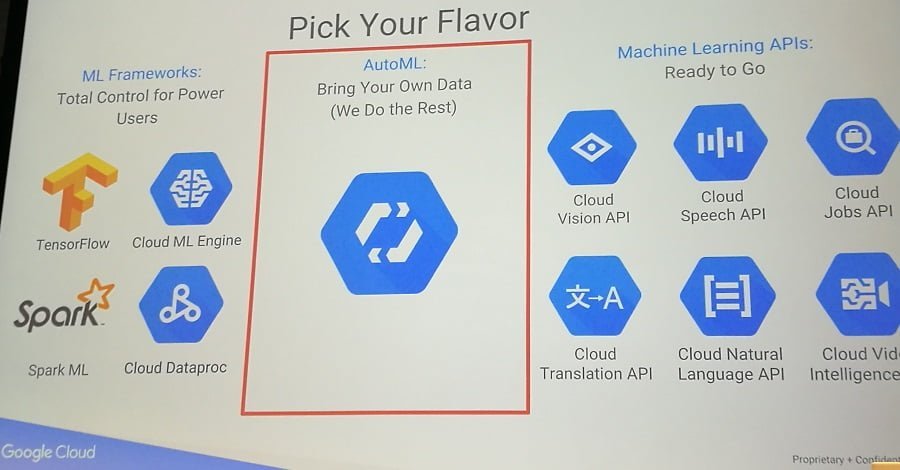
W ten sposób została przedstawiona ogólna koncepcja machine learning. Narzędzia i usługi związane z ML, do jakich daje nam dostęp Google, oraz bardziej szczegółowy proces budowy modelu ML opisał nam Lukman Ramsey. Jak wspomnieli wcześniejsi prelegenci, samouczące się systemy są wykorzystywane w Google od lat, jednak wysokie koszty prowadzenia badań i bardzo mała liczba wysokiej klasy specjalistów powoduje, że dostęp do tych rozwiązań jest bardzo utrudniony. Właśnie dlatego celem, jaki sobie postawiono w Google, jest możliwie szerokie rozpropagowanie tych narzędzi i uczynienie ich maksymalnie dostępnymi, jako usługi świadczone przez Google. Obecnie, oferują nam dostęp do:
- ML Frameworks,
- AutoML,
- Machine Learnings APIs.
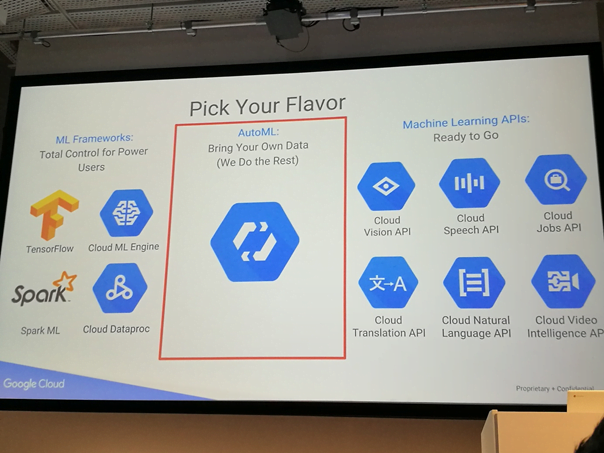
Najciekawszym rozwiązaniem jest AutoML – jak na prezentacji – „Bring Your Own Data (We Do the Rest)”. Nic dodać, nic ująć. Bardzo chętnie wypróbujemy możliwości tego narzędzia.
ML APIs to gotowe produkty o ustalonym wcześniej przeznaczeniu (np. rozpoznawanie mowy, rozpoznawanie odręcznego pisma) możesz ich użyć jak ”klocków” i niejako wbudować w swój produkt (np. strona, aplikacja mobilna). Wystarczy przekazać odpowiednie dane, np. przechwyconą komendę głosową do Cloud Speech API, a ono zwróci tekst. Dzięki temu nie musisz na nowo tworzyć rozpoznawania mowy, a zaoszczędzony czas poświęcasz na rozwijanie kluczowych funkcji w swojej aplikacji, która dzięki ML API może być obsługiwana głosowo (i to bez większych nakładów pracy z Twojej strony).
Ostatnia możliwość to ML Framework, jest to najbardziej zaawansowane rozwiązanie– tutaj, praktycznie nic nie jest ograniczeniem poza Twoimi potrzebami (oczywiście, jeżeli jesteś w stanie dostarczyć wystarczającą ilość danych o odpowiedniej jakości by umożliwić „uczenie się” modelu). W tym wypadku, Google proponuje indywidualna szkolenia, warsztaty i konsultacje ze swoimi ekspertami, ale wciąż potrzebna jest nam duża wiedza. Lukman podał ciekawy przykład wykorzystania ML, w który był osobiście zaangażowany – projekt autonomicznego statku prowadzony przez Rolls Royce’a.
Więcej przykładów praktycznego zastosowania zostało przedstawionych w drugiej części konferencji. Mieliśmy okazję posłuchać o tym, jak machine learning dosłownie uczy robotyczne ramiona chwytać przedmioty w NoMagic.ai, oraz jak pomogło dostarczać lepiej dopasowane odpowiedzi w Brainly. Najbliższe nam były dwie ostatnie prezentacje – dotyczyły możliwości wykorzystania ML w szeroko pojętym marketingu.

Jozo Kovac z Exponea próbował nam pokrótce przybliżyć jak wykorzystują ML do zwiększenia sprzedaży w sklepie internetowym. Pokazała nam automat, który generuje nam rekomendacje na podstawie zdjęcia produktu na stronie produktowej. Zastosowań takiego automatu może być wiele, jednym z najlepszych jest wyświetlanie rekomendacji z podobnymi produktami, gdy wybrany przez nas produkt jest niedostępny w sklepie. Dzięki temu, potencjalny klient zamiast wyjść z naszej strony, może zostać i zastanowić się nad wyborem innego, podobnego produktu (np. innej koszulki, która również ma średniej wielkości niebieski print na piersi, tak jak pierwotnie przez nas wybrana).
Na tym nie kończą się możliwości ML. Ciekawym przykładem była kwestia remarketowania odwiedzających naszą stronę. Machine learning może nam pomóc wybrać, na podstawie danych, najbardziej odpowiedni sposób na ponowne dotarcie do potencjalnego klient. Nie dość, że podejmie za nas decyzję czy użyć np. e-maila, smsa, powiadomienia pusch czy remarketingu AdWords, to jeszcze (przynajmniej w przypadku tych 3 pierwszych) pomoże wybrać najlepszą porę dnia na dotarcie do remarketowanej osoby. Jest to nie do przecenienia w przypadku maili – wybór odpowiedniej godziny może sprawić, że nasza oferta znajdzie się na samej górze skrzynki w momencie, gdy użytkownik będzie czytał swoje maile, a nie gdzieś poniżej całkowicie niewidoczne pomiędzy innymi wiadomościami. Przedstawione możliwości były bardzo interesujące, a do pełni szczęścia brakowało nam tylko studium rzeczywistego przypadku.
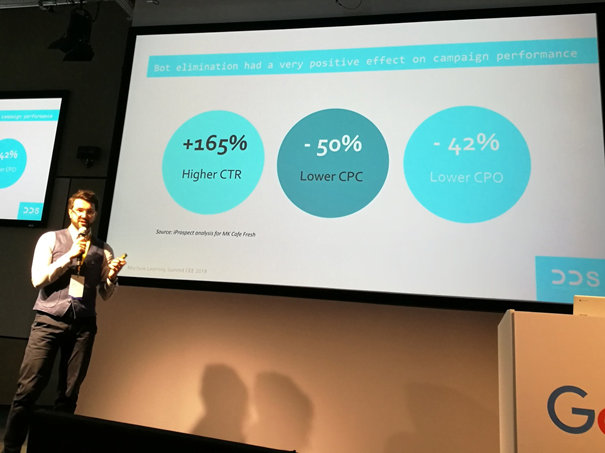
Case study nie zabrakło w prezentacji Arkadiusza Wiśniewskiego z iProspect. Na początku przedstawił niezbyt kolorowy obraz branży – wiele firm nie wykorzystuje danych ze swoich poprzednich działań, tergetuje głównie na demografie i lokalizację i nie posiada jednego miejsca, w którym integruje wyniki z wszystkich działań i systemów (CRM, systemy marketingowe itp.). Ostatni punkt jest najważniejszy, dzięki niemu otrzymujemy zagregowane dane, które potem możemy wykorzystać we wcześniej już wspomnianej „fazie uczenia” naszego modelu. Arkadiusz przedstawił jak dzięki ML udało im się ograniczyć liczbę reklam wyświetlanych botom i jak to wpłynęło na wyniki ich działań. Niestety, nie mógł się zbytnio zagłębiać w szczegóły, a szkoda – bardzo chętnie dowiedzielibyśmy się więcej!
Machine Learning Summit CEE było niezwykle ciekawym wydarzeniem, mimo że nie leżało stricte w polu naszych zainteresowań to bardzo się cieszymy, że mogliśmy w nim wziąć udział. Jeżeli tylko będziecie mieli okazje uczestniczyć w jakiejś konferencji organizowanej przez Google, wyczyśćcie swoje kalendarze tego dnia i nie zmarnujcie takiej okazji!

















