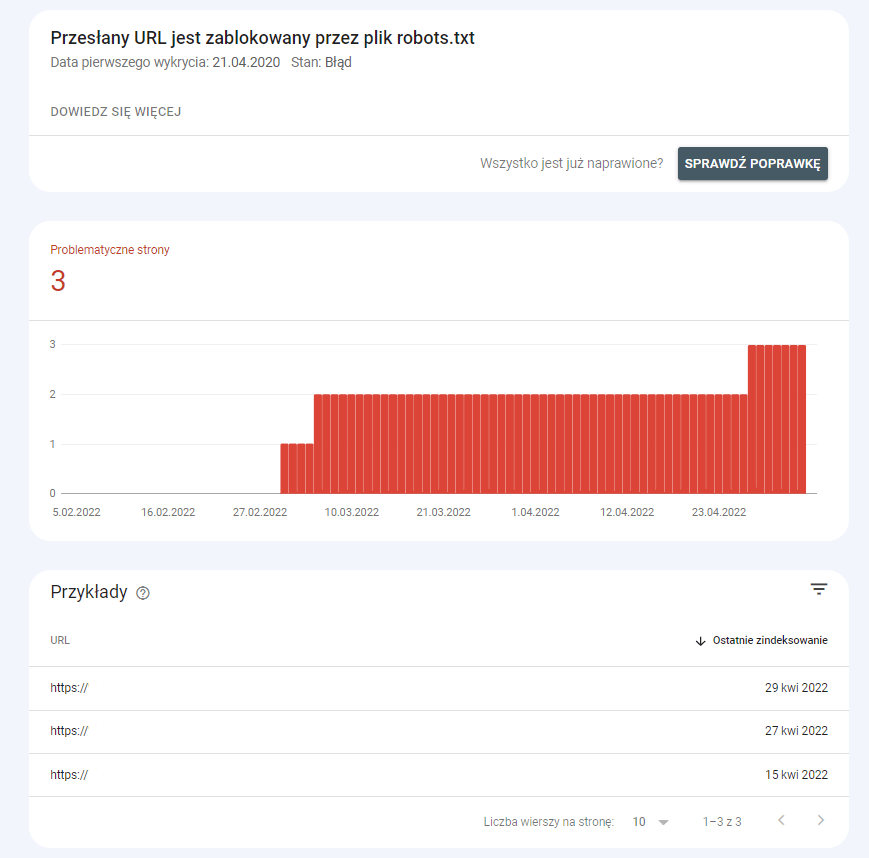
W raporcie “Stan”, który jest generowany regularnie przez Google Search Console, może pojawić się komunikat o błędzie informujący, że URL został zablokowany przez plik robots.txt. Co on właściwie oznacza i jak go naprawić?
Adres zablokowany przez robots.txt
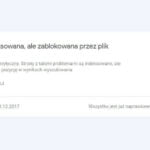
Komunikat, że “przesłany URL jest zablokowany przez plik robots.txt” oznacza, że strona, która została przesłana do zaindeksowania jest jednocześnie zablokowana w pliku robots.txt, co uniemożliwia indeksację. Powoduje to powstanie błędu, ponieważ prośba i dyrektywa wzajemnie się wykluczają.
Jak naprawić ten błąd?
Pierwszym krokiem w naprawie błędu jest zweryfikowanie pliku robots.txt. Można to zrobić np. testerem dostarczanym przez Google, które od razu wskaże element, który powoduje blokowanie indeksacji. W tym celu wystarczy rozwinąć panel boczny, w którym znajdują się narzędzia i wybrać opcję “Przetestuj blokowanie przez plik robots.txt”. Wówczas od razu sprawdzimy interesujący nas adres.
Kolejnym krokiem jest aktualizacja samego pliku robots.txt. Można go pobrać na kilka sposobów np. bezpośrednio ze strony, za pomocą dedykowanego narzędzia lub z Google Search Console. Po pobraniu i poprawieniu (lub usunięciu) elementu, który powodował błąd, wystarczy wgrać plik z powrotem do katalogu głównego strony. Proces wgrywania będzie różnił w zależności od wykorzystywanego oprogramowania i dostawcy usług hostingowych.
Naprawa może się skomplikować, gdy nie ma się dostępu lub uprawnień do edytowania pliku robots.txt. Wówczas trzeba skontaktować się z usługodawcą, poinformować o problemie i poprosić o poprawę.
Może się jednak zdarzyć, że strona została zablokowana w pliku robots.txt celowo, aby nie indeksowała się w Google. Wówczas należy sprawdzić mapę witryny, ponieważ strona mogła zostać w niej umieszczona automatycznie – np. na skutek działania skryptu generującego mapę z wszystkich istniejących adresów URL. Jeżeli tak się stało, aktualizujemy mapę witryny (czyli tzw. sitemapę). W takiej sytuacji należy również zadbać, aby ta strona oraz inne, które nie mają się indeksować, nie trafiały do mapy.
Więcej informacji: https://support.google.com/webmasters/answer/7440203?hl=pl#
O innych błędach w GSC pisaliśmy tutaj: