

11 września 2020 r. odbyła się konferencja online pt. Crawl & Indexation Summit organizowana przez BrightonSEO. Nasze specjalistki SEO zebrały dla Was garść informacji na temat indeksacji, crawlowania i linkowania wewnętrznego. Zapraszamy na pierwszą część poświęconą trzem webinarom:
- JavaScript – pobieranie i indeksowanie: najczęstsze mity i rzeczywiste problemy.
- Jak zmaksymalizować wydajność crawlowania dużej strony?
- Linkowanie wewnętrzne: Jak odkryć ukryty potencjał strony internetowej.
Webinar: JavaScript – pobieranie i indeksowanie: najczęstsze mity i rzeczywiste problemy
Celem tego wystąpienia było omówienie najczęstszych mitów dotyczących pobierania i indeksowania treści JavaScript, a także zidentyfikowanie rzeczywistych problemów związanych z nieprzetworzoną treścią JavaScript, które mogą mieć wpływ na szybkość, a w niektórych przypadkach na pobieranie i indeksowanie witryny. Webinar poprowadzony został przez Marię Amelie White – Head of Seo, FloristPro.
Główne zagadnienia webinaru to:
- Crawlowanie i indeksowanie
- Renderowanie Javascript
- Najpopularniejsze mity dotyczące Javascript
- Rzeczywiste problemy z Javascript i rozwiązania
Crawling&Indexing
Na wstępie prelegentka zapoznała odbiorców z definicją Crawlowania strony:
Proces crawlowania zaczyna się w momencie gdy boty wyszukiwarki wchodzą na stronę internetową. Następnie pobierają jej zasoby, takie jak: HTML, CSS, Javascript, grafikę, czy też linki umieszczone w kodzie. Google w pierwszej kolejności pobiera kod HTML, a JavaScript zostaje zakolejkowane do późniejszego renderowania. Po wszystkim adresy URL zostają wysłane do Google Caffeine – algorytm, który gromadzi i bardzo szybko indeksuje dane.
W tym momencie pojawia się pytanie, co dzieje się z JavaScript? Javascript poddawany jest tzw. Renderowaniu.
W przeszłości pobranie HTML było wystarczające dla większości stron internetowych. Niestety te czasy już minęły. Z powodu coraz to większej popularności korzystania z JavaScript podczas tworzenia stron internetowych, wyszukiwarka musi renderować stronę tak samo jak przeglądarka, żeby móc zobaczyć to samo co widzi użytkownik. Oznacza to że JavaScript jest przetwarzany w modelu DOM (Document Object Model).
Cały proces renderowania jest obsługiwany przez tzw. Web Rendering Service. Google stworzyło diagram przedstawiający jak działa proces:
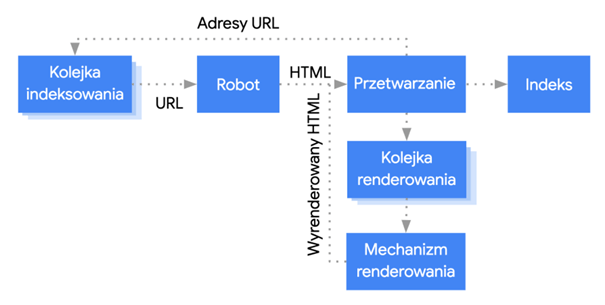
Proces ten nigdy się nie kończy.

Sprawdź, gdzie możesz nas spotkać!
Mity dotyczące JavaScritpt
JavaScript negatywnie wpływa na SEO
To nie do końca prawda. Negatywnie na stronę wpływać może nadużywanie go. JavaScript nie jest perfekcyjny, może być np. za ciężki i opóźniać ładowanie się strony, ale nie można twierdzić, że wpływa negatywnie na SEO.
Mechanizm renderujący czeka tylko 5 sekund żeby załadować stronę
To nieprawda. Nie ma ustalonego czasu na renderowanie.
JavaScript nie może być zaindeksowany
Może.
JavaScript zawsze wymaga dwuetapowego indeksowania (Two wave indexing of JavaScript)
Nie. Prelegentka w tym miejscu powołuje się na swoje doświadczenie w SEO i budowie stron internetowych. Sam John Mueller i Martin Splitt potwierdzili to jeszcze w zeszłym roku: https://www.youtube.com/watch?v=acr3i9UCCZ0&feature=emb_title
Najczęstsze problemy z JavaScript i jak sobie z nimi radzić?
Najczęściej spotykane problemy to:
- Problemy z buforowaniem.
- Długie ładowanie się obrazów.
- Crawl Budget –JavaScript obniża budżet crawlowania.
Prelegentka poleca narzędzia do testowania, które warto wykorzystać do wykrywania problemów z JavaScript:
- Lighthouse
- PageSpeed Insights
- Mobile Friendly Test
- Search Console
- Onely – identyfikuje problemy z indeksacją
Zalecana jest także dokumentacja, którą należy przeczytać dokładnie, nawet kilka razy, aby zrozumieć jak działa Crawling, jak radzić sobie z wolnym ładowaniem strony i problemami z JavaScrip:
- Crawling – https://webmasters.googleblog.com/2017/01/what-crawl-budget-means-for-googlebot.html
- Lazy loading – https://developers.google.com/search/docs/guides/lazy-loading
- Rozwiązywanie problemów z JavaScriptem związanych z wyszukiwarką – https://developers.google.com/search/docs/guides/fix-search-javascript
- Ahrefs – https://ahrefs.com/blog/javascript-seo/
- Selesti – https://www.selesti.com/knowledge-hub/busting-page-speed-myths-server-caching-code-splitting-and-server-location
Webinar: Jak zmaksymalizować wydajność crawlowania dużej strony?
https://crawlandindexation.heysummit.com/talks/how-to-maximize-your-sites-crawl-efficiency/
Dlaczego powinniśmy przejmować się crawl budget? Google podkreśla, że crawl budget nie jest problemem dla większości stron. Jeżeli jednak posiadasz duży serwis, w którym generowane jest mnóstwo nowego contentu i dodawane są nowe produkty, warto przyjrzeć się temu, jak Google indeksuje Twoją stronę. Niezeskanowane i nie zindeksowane zasoby nie są widoczne w wyszukiwarce, a co za tym idzie – nie powodują konwersji.
Czym jest crawl budget? Jest to liczba urli, które roboty Google mogą i chcą skanować. Istnieje zasadnicza różnica pomiędzy tymi dwoma określeniami. To, czy Googleboty mogą skanować zależy od kondycji strony, tzw. crawl health oraz od limitów crawlowania. Natomiast chcą skanować ważny i świeży content na stronie. Webinar Miracle Inameti-Archibong, Head of SEO w Erudite został podzielony na dwie części, obejmujące te zagadnienia.
Crawl health
Po pierwsze, aby dowiedzieć się, czy Google może crawlować twoją stronę, należy użyć crawlera, np. Screaming Frog lub Site Bulb. Dobrą praktyką jest podzielenie swojej strony na sekcje i skanowanie je systematycznie – dzięki temu unikniemy chaosu w swoich działaniach.
Aby ułatwić pracę sobie oraz robotom Google warto od początku wykluczyć z indeksu zasoby, które marnują crawl budget. Użytkownicy w Twoim serwisie mogą wyszukiwać i filtrować produkty? Wyklucz strony filtrowania, które nie tylko zużywają crawl budget, ale także mogą powodować duplikację treści.
Sprawdź w raporcie Google Search Console ile stron zostało zindeksowanych, a ile wykluczonych. Przyjrzyj się dokładnie, jakie strony zostały wykluczone – napraw błędnie ustawione canonicale oraz błędy 404.
Oprócz Google Search Console, istotnym źródłem danych są pliki Log File, z których możemy dowiedzieć się:
- czy skanowana jest strona mobilna czy desktopowa;
- roboty jakich wyszukiwarek skanują stronę;
- które urls są najczęściej crawlowane;
- jakie kody serwera są najczęściej zwracane;
- które strony są najważniejsze;
- jakie mamy straty w crawlowaniu ;
- co nie zostało zeskanowane.
Co wpływa na tzw. crawl health?
- Nawigacja fasetowa, czyli możliwość filtrowania produktów po cechach wspólnych (kolor, rozmiar, materiał). Generuje to mnóstwo dodatkowych url, których nie chcemy w indeksie.
- Generowanie stron dynamicznych o słabej jakości contentu (ang. thin content) – strony te nie niosą wartości dla użytkownika i nie powinny znajdować się w indeksie.
- Wydajność serwera.
- Pułapki i pętle – duże serwisy, które mają ustawione canonicale i przekierowania, które powodują pętle mogą zmylić googleboty i powodować utratę crawl budget.
- Orphan pages, czyli strony, które nie są podlinkowane linkami wewnętrznymi i nie znajdują się w strukturze strony.
- JavaScirpt & Ajax links.
Co wpływa na liczbę urli, które roboty wyszukiwarek chcą sprawdzić?
- Dobrej jakości, unikalny content, który jest chętnie czytany przez użytkowników
- Aktualna treść
Jak zmaksymalizować efektywność crawlowania strony?
- Optymalizacja site mapy oraz regularne jej aktualizowane, szczególnie w serwisach, w których jest dodawane dużo nowych treści i produktów.
- Rozważne używanie pliku robots.txt w celu informowania wyszukiwarki co ma zostać zaindeksowane, a co nie.
- Śledzenie i identyfikacja strat w crawlowaniu.
- Usunięcie starych site map z serwera.
Po zidentyfikowaniu wszystkich problemów warto użyć narzędzi, takich jak Google Search Console do zgłaszania stron do indeksacji. Logiczna struktura strony z podziałem na kategorie i podkategorie pomaga w indeksowaniu. Nawigacja oparta na tzw. okruszkach chleba, czyli breadcrumbs także w sposób czytelny informuje zarówno użytkowników jak i roboty Google o zawartości serwisu. I na koniec – zadbaj o linkowanie wewnętrzne, a zwłaszcza dodawanie linków z ważnych stron w serwisie do nowych treści, aby ułatwić robotom jej znalezienie.
Webinar: Linkowanie wewnętrzne: Jak odkryć ukryty potencjał strony internetowej
Webinar poprowadzony przez Jenny Halasz – prezes JLH Marketing. Prelegentka odpowiada na pytanie co zrobić, aby zoptymalizować proces linkowania wewnętrznego w swojej witrynie i zwiększyć szanse pojawienia się w TOP 5 wyników wyszukiwania.
Jenny przedstawia teorie stojące za optymalizacją linków wewnętrznych oraz przykłady wdrożenia takich rozwiązań, które skończyły się sukcesem.
W trakcie szkolenia dowiedzieliśmy się:
- jakie są możliwości optymalizacji linków wewnętrznych;
- jak podejmować mądre, oparte na danych, decyzje dotyczące struktury strony;
- jak bezpiecznie zaprojektować architekturę swojej witryny.
Mega Menu
Pierwszym tematem, który został poruszony był temat unikania w witrynie tzw. Mega Menu*, które wg prezenterki jest „out of balance”, czyli w luźnym tłumaczeniu zaburzają równowagę strony. W narzędziu Screaming Frog sprawdziła ona jak wygląda wskaźnik „Crawl Depth” (głębokość crawlowania) strony korzystającej z rozwiązania Mega Menu:

Oznacza to że Wszystkie podstrony witryny są linkowane z każdej podstrony witryny, co czyni architekturę witryny bardzo płaską.
* Mega Menu to nazwa nadana dużemu panelowi, który zawiera odnośniki do wszystkich podstron w witrynie.
Płaska architektura
Płaska architektura informacji (architektura informacji to sposób rozmieszczenia treści na stronie) ma wpływ na frazy kluczowe, na które wyświetlana jest strona i niestety często zdarza się sytuacja jak na poniższym screenie, tzn. występująca bardzo mała liczba fraz kluczowych, opisujących całą witrynę.

Case studies
Przykłady z życia, które przedstawia Jenny w swoim wystąpieniu:
- Czy powinienem zmienić strukturę strony, aby była mniej „płaska”?
W idealnym świecie – tak, aczkolwiek nie zawsze jest to możliwe. Jenny pracowała z witryną o bardzo płaskiej architekturze, ale stworzyła prawidłową strukturę linkowania wewnętrznego. Poszczególne podstrony zostały odpowiednio segmentowane, dodano nowe (bardziej szczegółowe) kategorie oraz uporządkowano linkowanie pomiędzy poszczególnymi stronami.
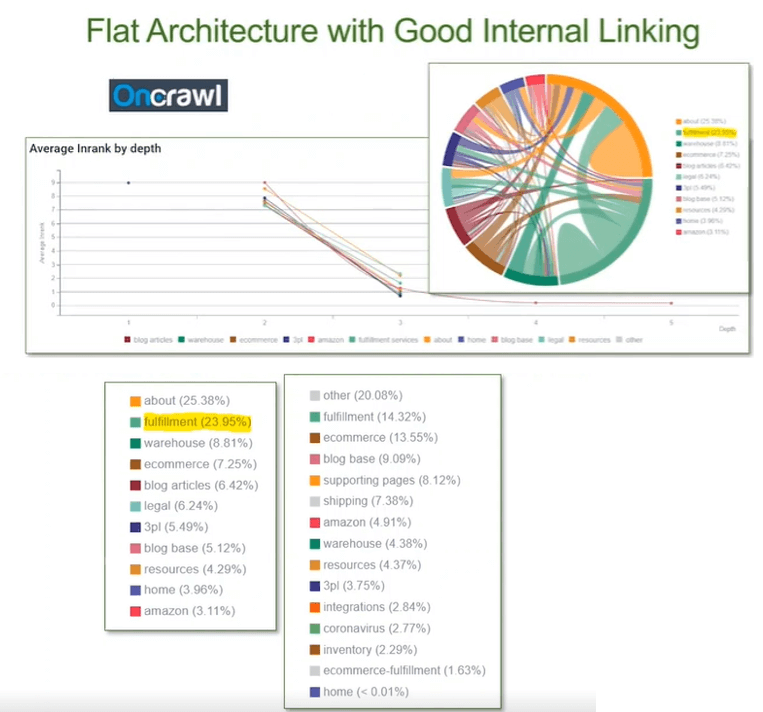
- Mój klient chce wyświetlać się na wyższej pozycji na frazę „alternative to Amazon FBA”.
(Jest to klient, który wykorzystuje sprzedażowy model „Dropshipping”)
W pierwszej kolejności Jenny (korzystając z narzędzia Oncrawl) sprawdziła wskaźnik Inrank – czyli wskaźnik, który mierzy popularność danej strony w witrynie. Dla każdej strony przypisywana jest ocena od 0-10. Największa popularność to oczywiście strony z 10. Inrank pomaga dowiedzieć się, czy strategia tworzenia linków jest właściwa. Oto wynik dla hasła „amazon”:
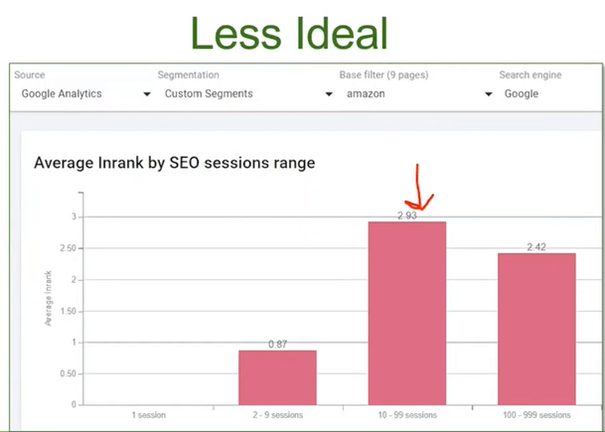
Po kliknięciu w drugi słupek (z najwyższym wskaźnikiem Inrank) pojawiły się szczegóły – istnieją 3 podstrony w witrynie, które zawierają odniesienie do sprzedaży na Amazonie. Największą „moc” posiada strona nr. 1 zaznaczona na czerwono:

Wniosek: Klient powinien wykorzystać istniejącą stronę i zoptymalizować ją pod pożądaną frazę oraz rozważyć połączenie jej z stroną nr.3, a następnie umieścić odnośnik do tej strony na stronie nr.2.
- Zbyt wiele linków w niewłaściwym miejscu.

W tym przykładzie Jenny pokazała, że należy uważać na rozmieszczenie linków w witrynie. Korzystając z wykresu drzewa katalogów w Screaming Frog można zobaczyć czy w witrynie istnieją takie obszary, do których prowadzi za dużo lub za mało linków. W tym wypadku bardzo duża moc linków przekazywana jest do podstron /glossary i /scholarship-program, co nie do końca jest dobrym rozwiązaniem ponieważ nie są to kluczowe strony w witrynie.
- Zła struktura linków
Kolejnym przykładem złej struktury linkowania wewnętrznego jest taka sytuacja:
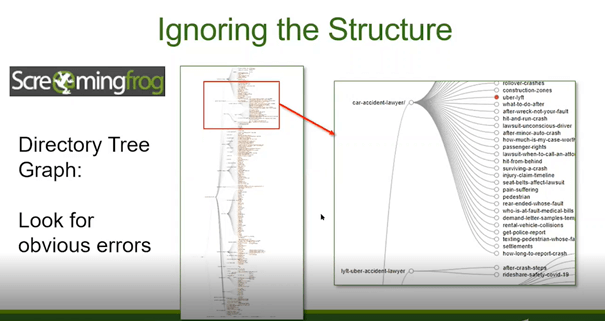
Jedna podstrona, która linkuje do bardzo dużej ilości innych podstron, jednocześnie będąc jedyną linkującą do nich częścią witryny.
Wniosek:
Linki wewnętrzne odgrywają kluczową rolę w SEO i przyczyniają się do sukcesów w pozycjonowaniu strony. Dlatego nigdy nie powinniśmy ich lekceważyć i starannie podchodzić do planowania strategii linkowania wewnętrznego, a wyniki będą mówić same za siebie. Tak jak u Jenny:
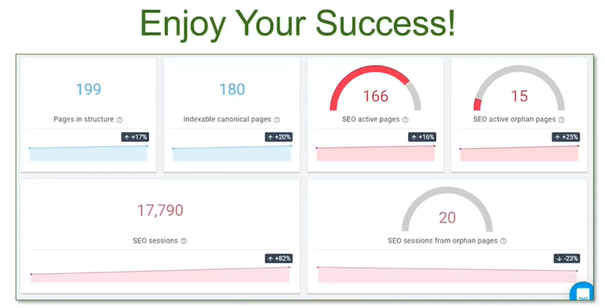
Kolejna część artykułu już niebawem na naszym blogu! Omówimy następne trzy wystąpienia:
- Indeksowanie JavaScript – co trzeba wiedzieć
- Najczęstsze błędy techniczne na stronie, które mogą powodować problemy z indeksacją.
- How to kick as internal linking.
















